
This chapter will discuss the following topics:
After studying this chapter, you should be able to:
For the purposes of this course, the word "argument" will be used to refer to any attempt to persuade another person that some claim is or is not true. This chapter will teach the basic analysis of a special kind of argument I call a "sampling argument." Sampling arguments are commonly used to support general statements. Generalizations are statements that cover the whole of some population, such as Americans, wombats, the water in the oceans, left-handed Armenian mole-diggers, Scotsmen with Irish names, tea-drinkers, trees, people who do horrible things to turnips... well, you get the idea. A sampling argument is an argument that starts with a "sample," a small group of taken by some method from a larger population, and then attempts to persuade us that a feature clearly seen in the sample must therefore also be a feature of the population.
It's important to remember that arguments are categorized by how they attempt to support their conclusions, not by the type of conclusion they have. The conclusion of an argument is a species of claim, and claims are different from the arguments that support them. Here are some claims .
Notice that none of these claims comes with any reason for you to believe it. Each is just a claim. None of them are arguments. Also notice that each of these claims is about all of something. The name for a claim that concerns all of something is "generalization." So these claims are all generalizations.
There are many ways of supporting a generalization, but this chapter is only concerned with one of them. This chapter is about sampling arguments, which have their own peculiar logical structure, their own problems and subtleties, and their own particular ways of going wrong.
Here are some sampling arguments .And now, for comparison, here are some arguments that are not sampling arguments.
The first thing to notice here is that the arguments in the second group have exactly the same conclusions as the arguments in the first group. These conclusions are all generalizations, but the type of conclusion does not control the type of argument . Arguments are sorted into types according to their "logical strategy", which means the way they go about supporting their conclusions. Arguments in the top group support their conclusions by alluding to a small group (the "sample") taken from a larger, encompassing group (the "population"), claiming that the sample has a certain "feature," and implying that because the sample has the feature, the population must also have the feature. (Arguments in the lower group use a whole bunch of different strategies, none of which we will worry about here.)
Technically, a "fact" is a something that cannot reasonably be disputed, an "opinion" is just something someone believes, and a "conclusion" is something someone thinks other people should believe. In terms of evidence, we can define a "fact" as a claim that is supported by compelling evidence, an "opinion" as a claim that someone thinks is supported by compelling evidence, and a conclusion as a claim that someone says is supported by compelling evidence.
Unfortunately, the words "fact" and "opinion" are occasionally badly misused, as in the following dialog:
Chuvaskaya.
So the teacher asked us to analyze this online debate between Doctor
Polyp and Professor Spleen. I think Dr. Polyp won the debate because
he pointed out that there are no documented cases of people dying as a
result of using marijuana, that increases in marijuana consumption
have not been followed by increases in disease the way the sharp rise
of cigarette smoking was followed by a sharp rise in lung cancer, and
that California has more-or-less legalized marijuana without
experiencing any noticeable increase in social problems. Professor
Spleen doesn't discuss these matters at all, and he gives no evidence
to support his claims that marijuana is more dangerous than alcohol
and tobacco, and should be illegal. So I think that Doctor Polyp's
argument for legalizing marijuana is better than Professor Spleen's
argument against it.
Flanders. I disagree. I think
your analysis is completely wrong. Look at the debate again. It's true
that Doctor Polyp says that noone has died from using marijuana, that
marijuana hasn't increased disease, and that California virtually
legalizing marijuana hasn't caused any problems, but Professor Spleen
has pointed out that marijuana is extremely dangerous and destructive,
and it should be absolutely illegal everywhere. So you can clearly see
that Professor Spleen has the facts while Doctor Spleen is just giving
his own personal opinion.
I want you to carefully examine the above dialog to determine who it is out of Doctor Polyp and Professor Spleen who actually has the facts and who is merely stating personal opinions. Notice that Spleen claims that marijuana is bad and should be illegal, while Polyp disagrees with this, so it follows that they have different conclusions. but the mere fact that two people disagree says nothing about which one of them has the facts. In fact, if all these two did was state opposing opinions, then we would have to say that neither of them had the facts. But also notice that while Spleen says nothing to support his conclusion, Polyp says quite a deal. Polyp gives reasons to believe his conclusion while Spleen does not. In general, if one side of an argument gives reasons and the other side doesn't, the side that doesn't give reasons cannot be said to "have the facts." A side that does not give reasons does not have the facts. Only sides that give reasons can ever be said to have the facts, and, even then those reasons don't always turn out to actually be facts. Furthermore, since Flanders doesn't mention Spleen raising any objections to Polyp's claims, we should assume, based on this dialog, that Spleen has not given us any reason to doubt Polyp's reasons. Thus, if anyone "has the facts" here, it is Polyp who has the facts, and Spleen who is merely giving his personal opinion.
For the purposes of this text, I want you to define a "fact" as a claim that is not actually disputed by anyone. Thus, if one side says that marijuana has never killed anyone, that it does not cause disease, and virtually legalizing it in California hasn't caused problems, and the other side does not dispute these claims, then those claims are the facts in this particular case.
The bottom line is, in this course, you should look to see whether or not a factual claim is disputed by the other side. If the claim is ignored or accepted by the other side, then that claim is a fact, at least as far as this class is concerned.
Define the following terms from memory and in your own words, and then check your answers against the way these terms are defined in the preceding text. If you can't do that, at least write out definitions of each of these terms in your own words. Make sure you write out these definitions in your own words. If you can't give your own definition of a term, then you don't understand that term.
When you make your definitions of these terms, try to come up with an example of something that fits each definition. If you have time, you could check and see if your example fits my definition as well as yours.
The essence of a sampling argument is the "sample." Usually, populations are so large that we cannot reasonably test the state of every member of that population. For instance, if we wanted to know what proportion of Scotsmen get tipsy (slightly drunk) on Hogmanay, we cannot possibly hire enough obervers to follow around every Scotsman around on the evening of December 31st. (Especially if we count female Scots as "Scotsmen" Oh, lets just call them "Scots."), so we're scre... I mean, so we have to fall back on looking at a much smaller number of Scots and extrapolating the results to all haggis-eatin', kilt-wearin' caber-tossers. (This is perhaps an unfair characterization of the Scots. Very few of them actually toss cabers.) So let's just hire people to follow around a randomly selected group of one million Scots next Hogmanay and to report on whether or not they get tipsy. Say that 75% of these randomly selected Scots get tipsy on Hogmanay, we could then make the following argument.
Exactly 75% of our sample got tipsy this Hogmanay, therefore 75% of all haggis-eaters got tipsy this Hogmanay.
Here's how the terminology of generalization matches up with this argument.
FactsThis is how a generalization works, if it works at all. A sample is taken, and it is argued that the state of the sample must be the same as the state of the population. If the state of the sample cannot reasonably be explained without assuming that the population has the same state, the argument is good. If we can reasonably explain the state of the sample without assuming that the population has the same state, the argument is no good, lousy, bogus, wack, heinous.... I'll stop now.
For another example, imagine that two people, call them "Jeeves" and "Wooster," are trying to figure out the overall composition of the following population. Imagine also that neither of them can see the population the way you can. (You can see that this population is extremely well mixed. In fact, there are only two deviations from perfect mixing. They appear in the top left and bottom right corners of the field. By some strange coincidence, that's where Jeeves and wooster take their samples from.) They know that it's composed of 2,600 colored dots, but that's about it. Neither of them has any idea of how the dots are distributed, or anything else besides the fact that it's made up of dots. And of course, neither of them knows that the population is made up of 650 red dots (25%), 650 blue dots (25%) and 1,300 green dots (50%) (You can see that this population is extremely well mixed. In fact, there are only two deviations from perfect mixing. They appear in the top left and bottom right corners of the field. By some strange coincidence, that's where Jeeves and Wooster take their samples from.) Now Jeeves takes a sample from the top left corner of the population (red line) while Wooster takes a sample from the bottom right corner, (blue line). Each of them then makes a claim about the composition of the population based on their samples.
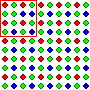

The reason Jeeves's argument is better than Wooster's argument is that argument Jeeves's sample is big enough to swallow it's imperfection in the mixing of the population (which means that his sample is representative of the population) while Wooster's sample is so small that it's imperfection crosses the sample border, distorting the result (which means that his sample isn't representative of the population). Are these samples too small? Well that depends on what we know about the structure of the population.
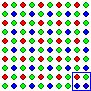
We saw above that it's possible to have a sample that's way too small to accurately represent the population it's taken from. However, it is sometimes the case that a population is structured in such a way that even a small sample can be perfectly representative, if it's taken the right way. A population is not always arranged as a chaotic mixture of individuals. Some populations are arranged in such a manner that we can take a very small sample with absolute confidence that the result will perfectly represent the composition of the population. For instance, consider the population of dots shown below. Imagine that we know that the population is structured in the way shown, but we don't know the colors of any of the rows. Now imagine we take the very, very, very, very small sample of exactly four dots comprising the first dot in each of the first four rows, as shown in the top left corner of the image. That's a sample of four out of four thousand. That's one per thousand, which means one tenth of one percent, or 0.001. Is that too small?

Our sample comes out 50 percent red, 25 percent blue and 25 percent green. Given that we know the structure of the population, what are the chances that the population is 50 percent red, 25 percent blue and 25 percent green?
Therefore, the following argument is very bad. (Technically, it commits what we call a red herring fallacy:)
It hasn't been proved that the dots in the picture above are 50% red, 25% blue and 25% green because the sample upon which that generalization is based is only 0.001 of the population, which is waaaaaaaay too small a sample.
The key fact here - the thing that makes this argument bad - is that the population is completely structured in alternating homogeneous rows of red, green, red and blue dots. It is this highly organized structure that allows a miniscule sample of just four dots to perfectly represent the composition of the whole population.
As a matter of fact, there is no limit to how small a sample can be. To see this, imagine a population of infinitely many dots, part of which is shown below. (The rest of the dots extend off your screen to the right.) This population is structured as you see here, in four rows of dots, each row being composed of dots of exactly the same color.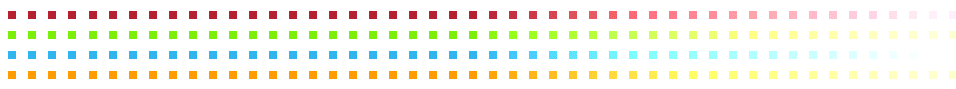

Finally, I want to introduce a distinction between "logical" and "illogical" criticism of an argument. In this text, I tend to use the word "logical" in a pretty broad sense, to mean any kind of thinking that has a chancemight help us to figure out the truth of the matter. Thus, I would say you're thinking logically if you're paying attention to the actual features of the argument, including details of the evidence offered, and the logical relationship that might hold between that evidence and the conclusions offered to explain it, even if, at that point, you happen to be making a mistake about that evidence or relationship. In other words, you're thinking logically if you are looking at things that do actually sometimes go wrong with arguments.
On the other hand, you are not thinking logically if you simply assume that somebody is wrong, or speculate about people's feelings or motives, or smugly asserts that you're above it all, or in any other way ignores the evidence or logic of someone else's argument.
Aussuming that Mutt has given an actual argument of some kind (however flawed it might be), the following are all examples of clearly illogical thinking. (The person who utters such inanities as this may say other things that are sensible, but whatever else that person says, the following statements are all absolutely illogical.)
Number one is illogical because the mere assertion that one argument is good cannot possibly prove anything about any other argument. Similarly, number two is illogical because the mere assertion that one person has proved something (which can only happen from a compelling argument), can never prove anything about anybody else's argument. Number three is not only illogical (because speculating about people's feelings cannot ever prove anything), it is also slanderous because it asserts without evidence that someone formed their belief illogically on the basis of feelings rather than facts. Number 4 is illogical for similar reasons. If Mutt is presenting any kind of argument at all, it is simply fales (and dishonest) to say that he's only stating his opinion. Number five is wrong in more subtle way. Ignorant and foolish people tend to use the wor "facts" simply to mean "things I believe," (and the word "opinions" for "things I don't believe"), which means that the phrase "Fred has the facts" is basically the same as "I believe Fred," which of course has absolutely no logical force. Number six might well be the stupidest thing anybody ever says about an argument. In my experience, it is only ever said by people who do not actually understand anything about the arguments they are dismissing as "ridiculous." If someone says this phrase to you, ask them pointedly to explain to you which side is right, and why, If they can't give a logical reason why one side is right and a logical reason to think that the other side has failed to prove it's points, then they are an idiot who mocks things they don't understand.
A good rule of thumb to identify illogical criticisms is to ask yourself if the "criticism" helps you understand what precisely is supposed to be wrong with the criticised argument. If the speaker is basically just especting you to take their word that the "criticised" argument is bad, then this "criticism" is not actually criticism in the sense of providing a critique of the argument.
of exposing an issue that
Many of these exercises consist of opposing pairs of arguments. They're called "opposing" because the arguers disagree with each other, and so each one in some way opposes the claims of the other argument.
(Answers at the end of the chapter.)
1.
Keyshawn. My survey says that Americans don't particularly care
about the proposal of adding a small federal tax on all computers and
modems sold in the United States. My people visited over a thousand
grocery stores in all kinds of neighborhoods in all fifty states. They
selected people from all walks of life and all income levels. They asked
twenty thousand people what they thought about the proposed tax. Most
hadn't heard of it, and didn't care about it when they did hear. Those who
cared were evenly distributed between mildly for and mildly against.
Dominique. Well, your information is wildly wrong. My company found
a way to reach one hundred thousand people in a very short period of time.
We did an e-mail poll of names selected at random from a very large
database of people who are considered preferred customers by our three
largest computer retailers. Ninety-five percent of our respondents had
heard of the tax, and eighty percent of all respondents were strongly
against it, so eighty percent of Americans are strongly against this tax.
Select the best critique of this dialog from among the following.
A. Keyshawn's argument is bad because he does not prove that Americans don't
particularly care about a small federal tax on all computers and modems sold
in the United States.
B. Keyshawn's argument is very weak. Just because 20,000 people from all
walks of life and income levels picked randomly from outside grocery stores
in all kinds of neighborhoods didn't care about the tax doesn't mean that
Americans in general don't care about the tax.
C. Keyshawn's argument is bad because of the small sample size.
D. Dominique's argument is bad because her sample was taken by e-mail, so it
excludes people who are not computer users, and it includes only people who
are preferred customers of computer retailers, which means that it includes
only people who are heavy computer users. Since the feature in question is
attitude towards a tax on computer equipment, this is not an independent
sample.
E. Dominique's argument is bad because she does not understand that
Keyshawn's sample is not too small.
F. Dominique's argument is bad because she is only stating her opinion
whereas Keyshawn has the facts.
2.
Deion. A lot of Muslims live in my neighborhood. There's
a mosque just up the street from my house, and Muslim people visit here
from all over the world. So I meet many, many Muslims from all different
countries as neighbors and friends. None of them want to forcibly convert
anyone to Islam. None of them know anyone who wants to forcibly convert
people to Islam. In fact, no Muslim I know or know of knows of anyone who
wants to forcibly convert people to Islam. So I don't think it's true that
a majority of muslims want to forcibly convert people to Islam.
Aryanna. You're so naive. Haven't you heard of the muslim
wars of conquest in 632-750 AD? Every Muslim in existence then was
committed to forcibly converting everyone in the world to Islam. And they
acted on this commitment, marching in massive armies into Arabia, North
Africa, Europe and Asia. They converted everyone they met at sword point,
and killed everyone who wouldn't convert. These actions were universally
applauded in the Muslim world, so a majority of Muslims strongly support
the conversion of people to Islam by force.
Say which of the following is the most appropriate critique for the
weakest argument in this dialogue?
A. Deion's argument is bad because a majority of Muslims strongly support
the conversion of people to Islam by force.
B. Deion's argument is bad because Aryanna proves that Deion's argument has
many logical flaws and problems. She proves that his argument is not
logically sound and that it commits several logical fallacies.
C. Deion's argument is bad because who are we to say whether Muslims want to
convert people by force or not?
D. Aryanna's argument is bad because realistically, modern Muslims are not
going to want to convert people to Islam by force.
E. Aryanna's argument is bad because she is using information from over a
thousand years ago. Societies can change very rapidly in only a few decades,
and it is unreasonable to think that present day Muslims must have the same
attitudes as Muslims who lived a thousand years ago.
F. Aryanna's argument is bad because the armies of conquest were actually
only a very small proportion of the total Muslim population. The Muslim
world that time included several million people, and the armies were only a
few tens of thousands of people. This means that only around one percent of
Muslims took part in the wars of conquest, so it's ridiculous to say that a
majority of Muslims at that time supported the use of force to convert
people.
For each of the following argument pairs, work out which argument is weaker by applying the
correct rules of analysis, and then write your own, original critique of the
weaker argument.
3. Deangelo. I don't think
many people believe in Bigfoot nowadays. A very reliable public opinion
company has been taking belief surveys every year for the last forty
years. Forty years ago about half the population took Bigfoot seriously,
but since then the percentage has slowly and steadily declined. The last
survey was eight months ago, and it found that only 20% of Americans think
Bigfoot might be real.
Micah. Well, your information is wrong! Just a few weeks ago, the
network of Fake-Jamaican Psychics gave a telephone survey to everyone who
called in for psychic or astrological advice. They had 27 million callers,
and 74 percent of those 27 million asserted that they firmly believed in
the reality of Bigfoot. Two weeks ago is very recent. 27 million is an
enormous sample for this kind of poll. No other opinion poll has used a
sample size of more than about 10,000, and many of those polls are
considered extremely reliable! So we can take it as proved that about 74
percent of Americans believe in Bigfoot.
4. Pierre. The latest AARP survey says that American seniors are
living longer and healthier lives than ever before. Old people make up
around 10 percent of American society, and respondents to the AARP survey
turned out to be both significantly healthier, and to have on average
lived considerably longer than a demographically identical group surveyed
only five years previously. I think this survey is reliable, because it is
based on responses from nearly the entire membership of the AARP, which is
of course composed entirely of seniors, and was supervised by the best
statistical survey analysts available.
Sonya. You're forgetting one thing. The AARP only makes up just
over 5 percent of the American population. How can you make any kind of
serious generalization based on a sample that is just 5 percent of the
population?
5. Freddie. I've got to say that in a weird way my respect for
conservatives has increased during the present crisis. I've talked to a
lot of conservatives about the present situation and most of them present
very reasonable case for their own side. They are not a bunch of
bloodthirsty warmongers, or knee-jerk jingoists who support any military
action no matter how ill-advised. Rather, the overwhelming majority of the
ones I've talked to are extremely upset by what they see as the necessity
for military action, and although I firmly disagree with their reasoning,
I have to say that most of them have taken a great deal of time and effort
to think through the issues. Let's face it, there's plenty of intelligent
conservatives out there.
Martina. I don't know how you can say that there are plenty of
intelligent conservatives out there. I've listened to A.M. radio dozens of
times and every Conservative talk show host I've ever heard has been an
ignorant, irrational blowhard who does nothing but disparage liberals
without ever bothering to find out what any actual liberals are actually
saying about anything! Yes, there's a lot of variety in these talk show
hosts. There are loud blustery idiots, and quiet vicious idiots, and
pedantic boring idiots, and self-important patronizing idiots. But there's
nobody who's willing to even begin to talk about the real issues and
arguments!
6. Gino. I'm worried about the sulfur content in that load of
crude oil you've got tied up at the docks there. I've just heard that it
has come from an oilfield where the crude usually has a high sulfur
content. That's a large capacity supertanker you've got there with over a
hundred separate storage tanks, so if I load all your oil into my
refinery, I could end up contaminating my entire works with sulfur
products.
Elsa. I anticipated your concern, and I dipped out this five gallon
sample from the No. 42 hold before I came over to your office. Your own
lab has certified that it has a very low sulfur content, so you don't have
to be concerned about the sulfur content of my oil.
7. Kathy. My cousin just came back from a business trip to Viet
Nam. She said the people were nice enough, but she thought there was an
undercurrent of resentment and suspicion towards Americans among most of
the people she dealt with there. I guess the Vietnamese over there are
still not quite as friendly towards American business people as people in
other parts of the world.
Madisen. Your cousin is dead wrong. All the people in Viet Nam love
and admire Americans. After the Japanese occupiers surrendered, Ho Chi
Minh and other Vietnamese leaders welcomed the Americans in as liberators
and supporters of Vietnamese independence. Why, love and admiration for
America was part of the Vietnamese language at that time. People used to
say "oh, to be as rich and wise as an American!" Does that sound to you
like people who are suspicious and resentful of Americans?
8. Gideon. You know you thought that we would never be
able to get any kind of accurate idea about the composition of the Earth's
core? Well, scientists have discovered that a massive meteor or asteroid
whacked into the Earth while it was still relatively hot, and the shock
wave kicked up some of the core material through the soft mantle and
crust. The crust was solid enough by then to hold this material in place.
Although some of the material was exposed by erosion, a lot of it was
protected from the elements by being buried in stable rock structures.
This material was shielded from water and other kinds of erosion, and
scientists were able to recover a sample. The samples were 90% iron and
10% nickel, there is nothing that can turn into nickel-iron over time, and
nickel-iron won't turn into anything else if it's kept away from water and
air down in the core, so the Earth's core is 90% iron and 10% nickel
Anaya. Wait a minute! That asteroid impact must have been
over ten billion years ago. Ten billion years must be the oldest sample
ever taken in science! We commonly discard hundred-year-old samples as too
old, and we don't even look at some thousand year old samples. Your sample
is ten million times as old as that, so it can't possibly be any good.
Study Questions
9. What do we call a small, examined group chosen from some larger,
otherwise unexamined group for purposes of answering some question about the
composition of the larger group?
10. What do we call that larger group?
11. What to we call the particular aspect of the population we're
looking at?
12. What do we call it when the small group is very, very likely to have the
same composition as the larger group?
13. What do we call it when the small group is not likely to have
the same composition as the larger group?
14. Is it true that an argument that is based on a sample that is very old
is always a hasty generalization?
15. Is it true that an argument that is based on a sample that is very small
is always a hasty generalization?
16. Is it true that an argument that uses a non-random sample is always a
hasty generalization?
17. Is it true that a very old sample can still be a good sample?
18. Is it true that a very small sample can still be a good sample?
19. Is it true that a sample that was not taken randomly can still be a good
sample?
20. Is 1% always too small? Is 50% always big enough? Explain
21. Is 1000 years always too old? Is 1 year always recent enough? Explain.
22. Is it true that some populations are too complicated to be properly
represented even by a very large sample?
23. Is it true that some populations change too rapidly to be properly
represented by even by a very recent sample?
24. in the context of sampling arguments, what is the difference between
hasty generalization and red herring?
25. Explain the three ways to commit red herring when criticizing a
generalization.
26. What are the three ways a sampling argument can go wrong?
27. What does it mean to say that a sampling method is "dependant?
28. What kinds of biases are a problem? What kinds of biases are not a
problem?
For more practice, you can download and
do the practice/makeup exercises. (Make
sure the document margins are set to 0.5 inches or narrower.)
Exercise Answers
1. Only critique D is any
good here, because it is the only one that mentions the key fact that
the poll was taken exclusively from people who buy a lot of computer
equipment. None of the other answers gave any reason at all to think that
the argument they referred to had any logical problems. Critique A fails
because all it does is say that Keyshawn does not prove his point without
giving any reason to think that Keyshawn has failed to prove his point.
Critique B actually has exactly the same problem, except that it takes the
time to describe Keyshawn's argument. Saying that an argument does not work
is not the same as proving that it does not work. Critique C fails because
it does not give any reason to think that Keyshawn's sample is too small for
this population. Critique E is not only bad, but insulting since it without
foundation accuses Dominique of failing to understand the situation. Instead
of giving reasons against Dominique's argument, critique E purports to look
inside her mind and find her wanting. This is never a legitimate argument.
Critique F is, of course, the worst kind of muddy thinking.
2. Critique E is correct. It is the only critique that
focuses on the key fact that the data Aryanna uses is over a thousand years
old. Critique A simply repeats the opposing conclusion without giving any
criticism of Deion's argument. Critique B is worthless because it simply
makes a series of unfounded claims about Deion's argument. Critique C is not
a critique but an insult. It simply repeats the opposing conclusion with an
unfounded accusation that Aryanna is being unrealistic. Critique F
completely misses the point of Aryanna's argument. She was not arguing that
most of the Muslims at that time took part in the wars of conquest, she was
pointing out that most of the Muslims at that time supported the wars of
conquest.
3. Micah's argument is weaker because his
sample consists entirely of people who believe in psychics and astrology.
Like Bigfoot, these are both things that mainstream science discounts, so
this group is composed entirely of people who tend to disagree with
mainstream science about psychics and astrology. This makes Micah's sample
unrepresentative because the American population also includes large numbers
of people who accept mainstream science and therefore disbelieve in things
like psychics, astrology and Bigfoot. Thus the proportion of people who
believe in Bigfoot is likely to be smaller in the general population than it
is in Micah's sample of people who believe in psychics and astrology. (The
fallacy here is dependent sample. The key fact here is that people who
believe in psychics and astrology are much more likely to believe in Bigfoot
than people who don't believe in psychics and astrology.)
4. Sonya makes two mistakes. First, she thinks that 5 percent
is too small a sample. In a properly conducted study, 5 percent is plenty.
However, Sonya makes another mistake. Pierre's generalization does not cover
the whole American population. It just covers the 10 percent that are
seniors. 5 percent is half of 10 percent, so Pierre's sample is 50 percent
of his population, not 5 percent. (Sonya's fallacy is a red herring, because
she is talking about something that is not relevant to the issue. The key
fact here is that Pierre's survey covers half of the population he's talking
about, which is an enormous sample when you're talking about a variable that
only has two possible values: healthier, and not healthier.)
5. Martina's argument is weaker because her sample is dependent.
Her sample might be thought to be inadequate as well because, while there
are tens of millions of conservatives in this country, only a hundred or so
have radio shows. However, we are talking about a variable that has only two
values, intelligent and unintelligent. If this sample was truly random, a
sample size of one hundred would be perfectly adequate. However, we have
reason to think that the sample is dependent. First, we have Freddie's
unopposed evidence that intelligent conservatives do exist, and there is the
fact that talk show hosts are selected on the basis of entertainment value
rather than intelligence. It is a sad fact of modern society that idiots are
often considered to be more entertaining than intelligent people, so it
is perfectly reasonable to think that the people who select talk show hosts
have a strong preference for idiots. (The fallacy here is dependent sample,
and the key fact is that talk show hosts are expected to be entertaining
rather than intelligent.) Another way to understand this exercise is to look at the difference
between the two conclusions. Both samples are recent, both are small, and
neither is randomly chosen from the population. But look at the difference
in their conclusions. Freddie argues that there are "plenty" of intelligent
conservatives, while Martina argues that there are no intelligent
conservatives. Freddie's conclusion could be true, and Martina's conclusion
false, even if AM radio is populated by idiots, since only a few
conservatives have radio shows. However, Martina's conclusion is that no
intelligent conservatives exist, which would imply that the intelligent
conservatives that Freddie is talking about do not exist. Since Martina has
given no reason to think that there is anything wrong with Freddie's survey,
we should conclude that the intelligent conservatives he talks about do in
fact exist. they do exist, Martina's conclusion must be wrong, and her
argument is a hasty generalization from a small sample. Since Freddie's
conclusion is much weaker than Martina's, his argument is much stronger.
6. Elsa has the weaker argument. Her sampling method
is inadequate because, firstly, the population consists of one hundred
separate storage tanks and there is no guarantee that the population is
perfectly mixed. Secondly, Elsa chose the sample herself, and so there is no
guarantee that he did not accidentally select the one tank in the tanker
that was free of sulfur. (And there is also the possibility that she
unconsciously selected oil from a tank she subconsciously knew to be low in
sulfur.) (The fallacy here is inadequate sample. The key fact is that there
is no guarantee that the oil in the whole tanker is perfectly mixed.)
7. Madisen's
argument is weaker because she is using data from the period just
after World War II, which was over sixty years ago, and public attitudes can
change considerably in that amount of time. (The fallacy here is obsolete
sample, the key fact here is that her sample is over sixty years old, and
attitudes can change enormously in that amount of time.)
8. Anaya's
argument is weaker. The amount of time since the asteroid impact does
not matter because there is no known substance that could have changed into nickel-iron
in any amount of time, under those conditions, so the only way that the sample could be nickel-iron
now unless it was nickel-iron when it was kicked up into the crust. And
since nickel-iron will not break down if it is protected from water and air
the way core material is protected, the fact that the core was nickel-iron
then means that it is nickel-iron now. (Anaya's fallacy is red herring
because she is talking about something that really doesn't matter. The key
facts here are that nothing turns into nickel iron, and nickel-iron is
stable under core conditions.)
9. A "sample."
10. The "population."
11. The "feature" or the "variable."
12. "Representative."
13. "Unrepresentative."
14. No.
15. No.
16. No.
17. Yes, of course.
18. Yes, of course.
19. Yes, and often is a better sample than a random sample.
20. No and no. It depends on the structure of the population.
21. No and no. It depends on the rate at which the population is likely to
change.
22. Yes.
23. Yes.
24. Hasty generalization is a problem with the way a sampling argument was
constructed. Red herring is attacking a sampling argument on the basis of
something that isn't really a problem.
25. Saying the sample size is too small when it is actually adequate for the
method used and the structure of the population. Saying the sample is too
old when we have no reason to think that the sample or the population has
changed since the sample was taken. Saying that the argument is bad because
the sample is not random when the method used is actually appropriate for
this particular population structure.
26. The sample size can be too small for the number of values possible for
the given variable. The sample could have been taken long enough ago that
either the population or the sample could easily have changed in the
meantime. The sample could have been taken by method that is not independent
of the feature.
27. A sampling method is dependent when members of the population that have
the feature are more or less likely to be included in the sample than
members of the population that do not have the feature. A sample is only
independent member of the population with the feature is exactly as likely
to be included in the sample as a member of the population without the
feature.
28. The only kind of "bias" that is ever a problem is when the sampling
method is dependent. Other things that are called "bias" are not a problem.
For more practice, you can download and
do the practice/makeup exercises. (Make
sure the document margins are set to 0.5 inches or narrower.)
Copyright © 2010 by Martin C. Young
